How to reduce retrieval latency
This guide assumes familiarity with the following concepts:
One way to reduce retrieval latency is through a technique called "Adaptive Retrieval".
The MatryoshkaRetriever uses the
Matryoshka Representation Learning (MRL) technique to retrieve documents for a given query in two steps:
First-pass: Uses a lower dimensional sub-vector from the MRL embedding for an initial, fast, but less accurate search.
Second-pass: Re-ranks the top results from the first pass using the full, high-dimensional embedding for higher accuracy.
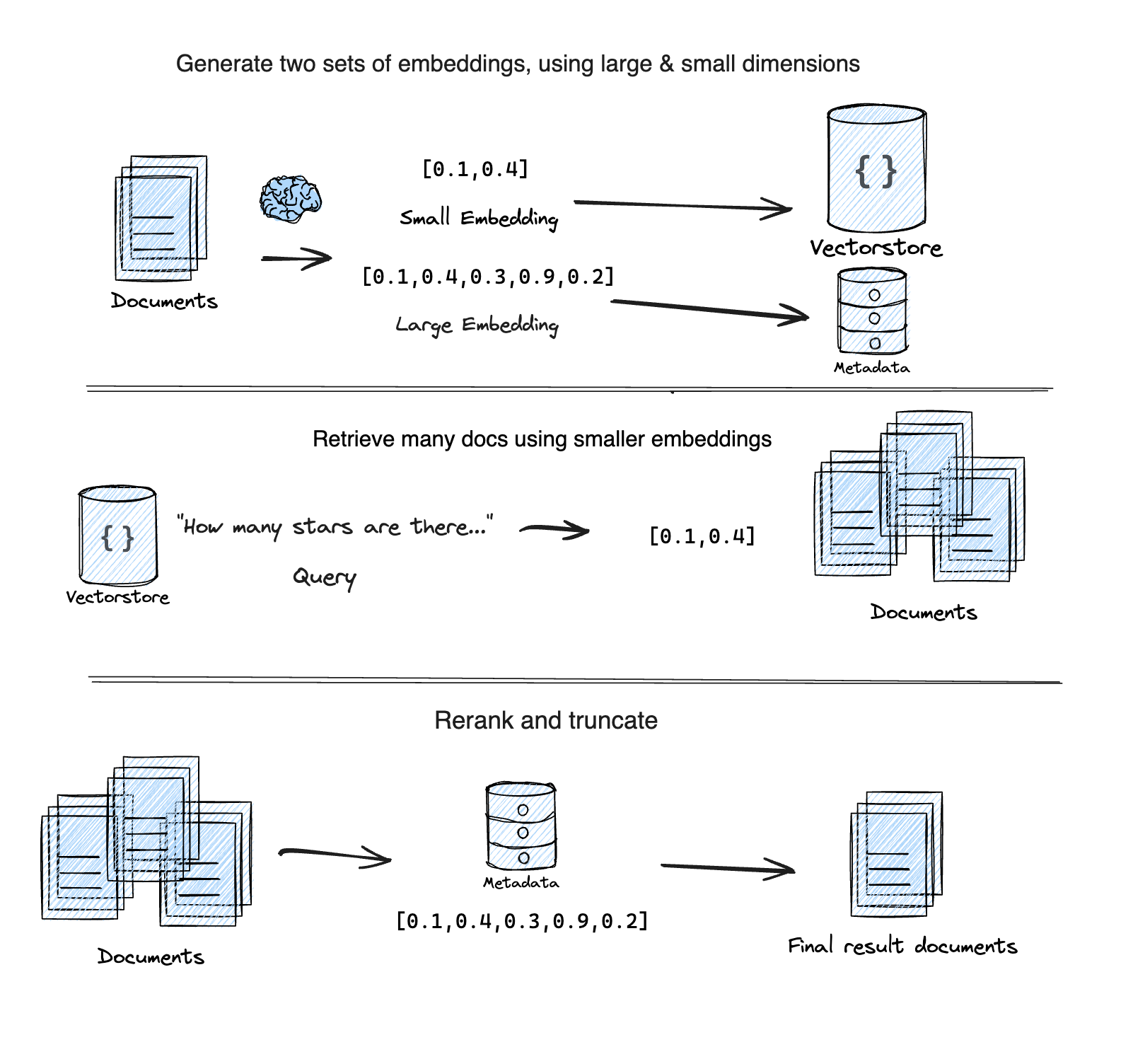
It is based on this Supabase blog post "Matryoshka embeddings: faster OpenAI vector search using Adaptive Retrieval".
Setup
- npm
- Yarn
- pnpm
npm install @langchain/openai @langchain/community
yarn add @langchain/openai @langchain/community
pnpm add @langchain/openai @langchain/community
To follow the example below, you need an OpenAI API key:
export OPENAI_API_KEY=your-api-key
We'll also be using chroma for our vector store. Follow the instructions here to setup.
import { MatryoshkaRetriever } from "langchain/retrievers/matryoshka_retriever";
import { Chroma } from "@langchain/community/vectorstores/chroma";
import { OpenAIEmbeddings } from "@langchain/openai";
import { Document } from "@langchain/core/documents";
import { faker } from "@faker-js/faker";
const smallEmbeddings = new OpenAIEmbeddings({
model: "text-embedding-3-small",
dimensions: 512, // Min number for small
});
const largeEmbeddings = new OpenAIEmbeddings({
model: "text-embedding-3-large",
dimensions: 3072, // Max number for large
});
const vectorStore = new Chroma(smallEmbeddings, {
numDimensions: 512,
});
const retriever = new MatryoshkaRetriever({
vectorStore,
largeEmbeddingModel: largeEmbeddings,
largeK: 5,
});
const irrelevantDocs = Array.from({ length: 250 }).map(
() =>
new Document({
pageContent: faker.lorem.word(7), // Similar length to the relevant docs
})
);
const relevantDocs = [
new Document({
pageContent: "LangChain is an open source github repo",
}),
new Document({
pageContent: "There are JS and PY versions of the LangChain github repos",
}),
new Document({
pageContent: "LangGraph is a new open source library by the LangChain team",
}),
new Document({
pageContent: "LangChain announced GA of LangSmith last week!",
}),
new Document({
pageContent: "I heart LangChain",
}),
];
const allDocs = [...irrelevantDocs, ...relevantDocs];
/**
* IMPORTANT:
* The `addDocuments` method on `MatryoshkaRetriever` will
* generate the small AND large embeddings for all documents.
*/
await retriever.addDocuments(allDocs);
const query = "What is LangChain?";
const results = await retriever.invoke(query);
console.log(results.map(({ pageContent }) => pageContent).join("\n"));
/**
I heart LangChain
LangGraph is a new open source library by the LangChain team
LangChain is an open source github repo
LangChain announced GA of LangSmith last week!
There are JS and PY versions of the LangChain github repos
*/
API Reference:
- MatryoshkaRetriever from
langchain/retrievers/matryoshka_retriever - Chroma from
@langchain/community/vectorstores/chroma - OpenAIEmbeddings from
@langchain/openai - Document from
@langchain/core/documents
Due to the constraints of some vector stores, the large embedding metadata field is stringified (JSON.stringify) before being stored. This means that the metadata field will need to be parsed (JSON.parse) when retrieved from the vector store.
Next steps
You've now learned a technique that can help speed up your retrieval queries.
Next, check out the broader tutorial on RAG, or this section to learn how to create your own custom retriever over any data source.