Classify Text into Labels
Tagging means labeling a document with classes such as:
- sentiment
- language
- style (formal, informal etc.)
- covered topics
- political tendency
Overview
Tagging has a few components:
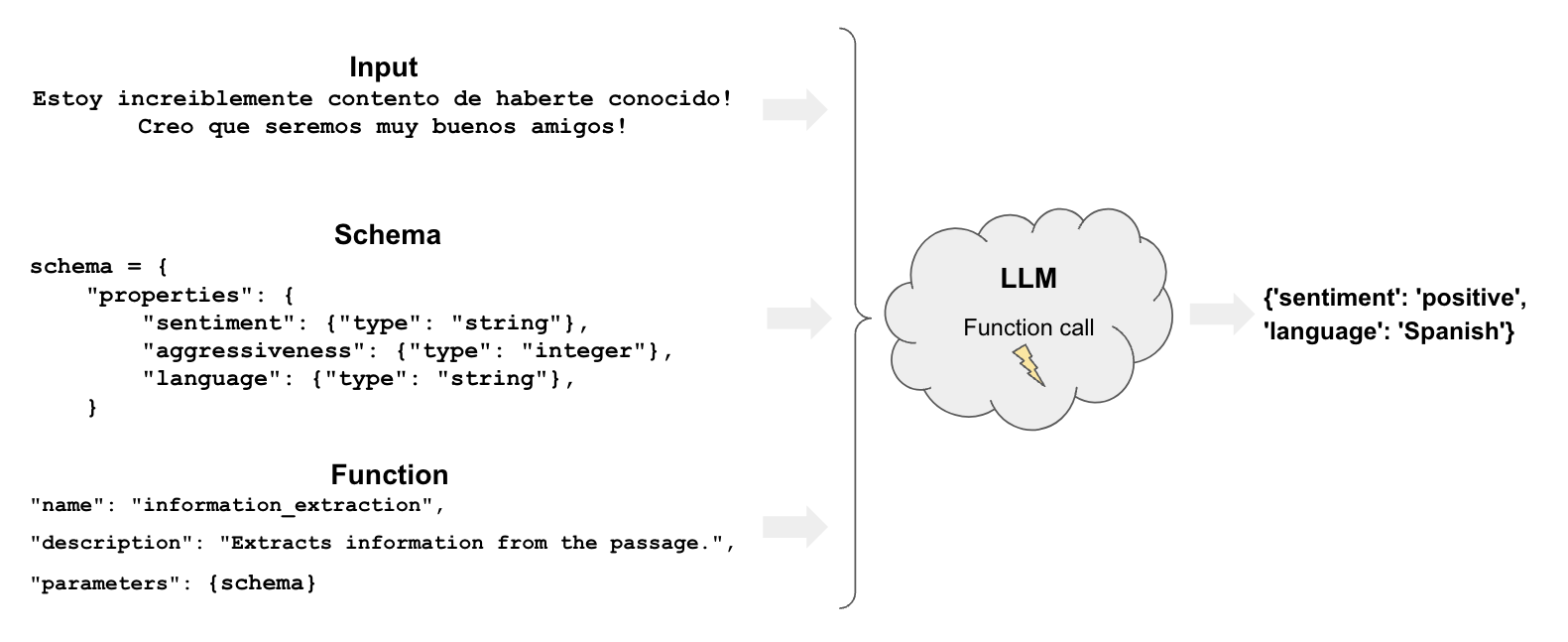
function: Like extraction, tagging uses functions to specify how the model should tag a documentschema: defines how we want to tag the document
Quickstart
Let’s see a very straightforward example of how we can use tool calling
for tagging in LangChain. We’ll use the .withStructuredOutput(),
supported on selected chat models.
Pick your chat model:
- Groq
- OpenAI
- Anthropic
- Google Gemini
- FireworksAI
- MistralAI
- VertexAI
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/groq
yarn add @langchain/groq
pnpm add @langchain/groq
Add environment variables
GROQ_API_KEY=your-api-key
Instantiate the model
import { ChatGroq } from "@langchain/groq";
const llm = new ChatGroq({
model: "llama-3.3-70b-versatile",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/openai
yarn add @langchain/openai
pnpm add @langchain/openai
Add environment variables
OPENAI_API_KEY=your-api-key
Instantiate the model
import { ChatOpenAI } from "@langchain/openai";
const llm = new ChatOpenAI({
model: "gpt-4o-mini",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/anthropic
yarn add @langchain/anthropic
pnpm add @langchain/anthropic
Add environment variables
ANTHROPIC_API_KEY=your-api-key
Instantiate the model
import { ChatAnthropic } from "@langchain/anthropic";
const llm = new ChatAnthropic({
model: "claude-3-5-sonnet-20240620",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/google-genai
yarn add @langchain/google-genai
pnpm add @langchain/google-genai
Add environment variables
GOOGLE_API_KEY=your-api-key
Instantiate the model
import { ChatGoogleGenerativeAI } from "@langchain/google-genai";
const llm = new ChatGoogleGenerativeAI({
model: "gemini-2.0-flash",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/community
yarn add @langchain/community
pnpm add @langchain/community
Add environment variables
FIREWORKS_API_KEY=your-api-key
Instantiate the model
import { ChatFireworks } from "@langchain/community/chat_models/fireworks";
const llm = new ChatFireworks({
model: "accounts/fireworks/models/llama-v3p1-70b-instruct",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/mistralai
yarn add @langchain/mistralai
pnpm add @langchain/mistralai
Add environment variables
MISTRAL_API_KEY=your-api-key
Instantiate the model
import { ChatMistralAI } from "@langchain/mistralai";
const llm = new ChatMistralAI({
model: "mistral-large-latest",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/google-vertexai
yarn add @langchain/google-vertexai
pnpm add @langchain/google-vertexai
Add environment variables
GOOGLE_APPLICATION_CREDENTIALS=credentials.json
Instantiate the model
import { ChatVertexAI } from "@langchain/google-vertexai";
const llm = new ChatVertexAI({
model: "gemini-1.5-flash",
temperature: 0
});
Let’s specify a Zod schema with a few properties and their expected type in our schema.
import { ChatPromptTemplate } from "@langchain/core/prompts";
import { z } from "zod";
const taggingPrompt = ChatPromptTemplate.fromTemplate(
`Extract the desired information from the following passage.
Only extract the properties mentioned in the 'Classification' function.
Passage:
{input}
`
);
const classificationSchema = z.object({
sentiment: z.string().describe("The sentiment of the text"),
aggressiveness: z
.number()
.int()
.describe("How aggressive the text is on a scale from 1 to 10"),
language: z.string().describe("The language the text is written in"),
});
// Name is optional, but gives the models more clues as to what your schema represents
const llmWihStructuredOutput = llm.withStructuredOutput(classificationSchema, {
name: "extractor",
});
const prompt1 = await taggingPrompt.invoke({
input:
"Estoy increiblemente contento de haberte conocido! Creo que seremos muy buenos amigos!",
});
await llmWihStructuredOutput.invoke(prompt1);
{ sentiment: 'positive', aggressiveness: 1, language: 'Spanish' }
As we can see in the example, it correctly interprets what we want.
The results vary so that we may get, for example, sentiments in different languages (‘positive’, ‘enojado’ etc.).
We will see how to control these results in the next section.
Finer control
Careful schema definition gives us more control over the model’s output.
Specifically, we can define:
- possible values for each property
- description to make sure that the model understands the property
- required properties to be returned
Let’s redeclare our Zod schema to control for each of the previously mentioned aspects using enums:
import { z } from "zod";
const classificationSchema2 = z.object({
sentiment: z
.enum(["happy", "neutral", "sad"])
.describe("The sentiment of the text"),
aggressiveness: z
.number()
.int()
.describe(
"describes how aggressive the statement is on a scale from 1 to 5. The higher the number the more aggressive"
),
language: z
.enum(["spanish", "english", "french", "german", "italian"])
.describe("The language the text is written in"),
});
const taggingPrompt2 = ChatPromptTemplate.fromTemplate(
`Extract the desired information from the following passage.
Only extract the properties mentioned in the 'Classification' function.
Passage:
{input}
`
);
const llmWithStructuredOutput2 = llm.withStructuredOutput(
classificationSchema2,
{ name: "extractor" }
);
Now the answers will be restricted in a way we expect!
const prompt2 = await taggingPrompt2.invoke({
input:
"Estoy increiblemente contento de haberte conocido! Creo que seremos muy buenos amigos!",
});
await llmWithStructuredOutput2.invoke(prompt2);
{ sentiment: 'happy', aggressiveness: 1, language: 'spanish' }
const prompt3 = await taggingPrompt2.invoke({
input: "Estoy muy enojado con vos! Te voy a dar tu merecido!",
});
await llmWithStructuredOutput2.invoke(prompt3);
{ sentiment: 'sad', aggressiveness: 5, language: 'spanish' }
const prompt4 = await taggingPrompt2.invoke({
input: "Weather is ok here, I can go outside without much more than a coat",
});
await llmWithStructuredOutput2.invoke(prompt4);
{ sentiment: 'neutral', aggressiveness: 1, language: 'english' }
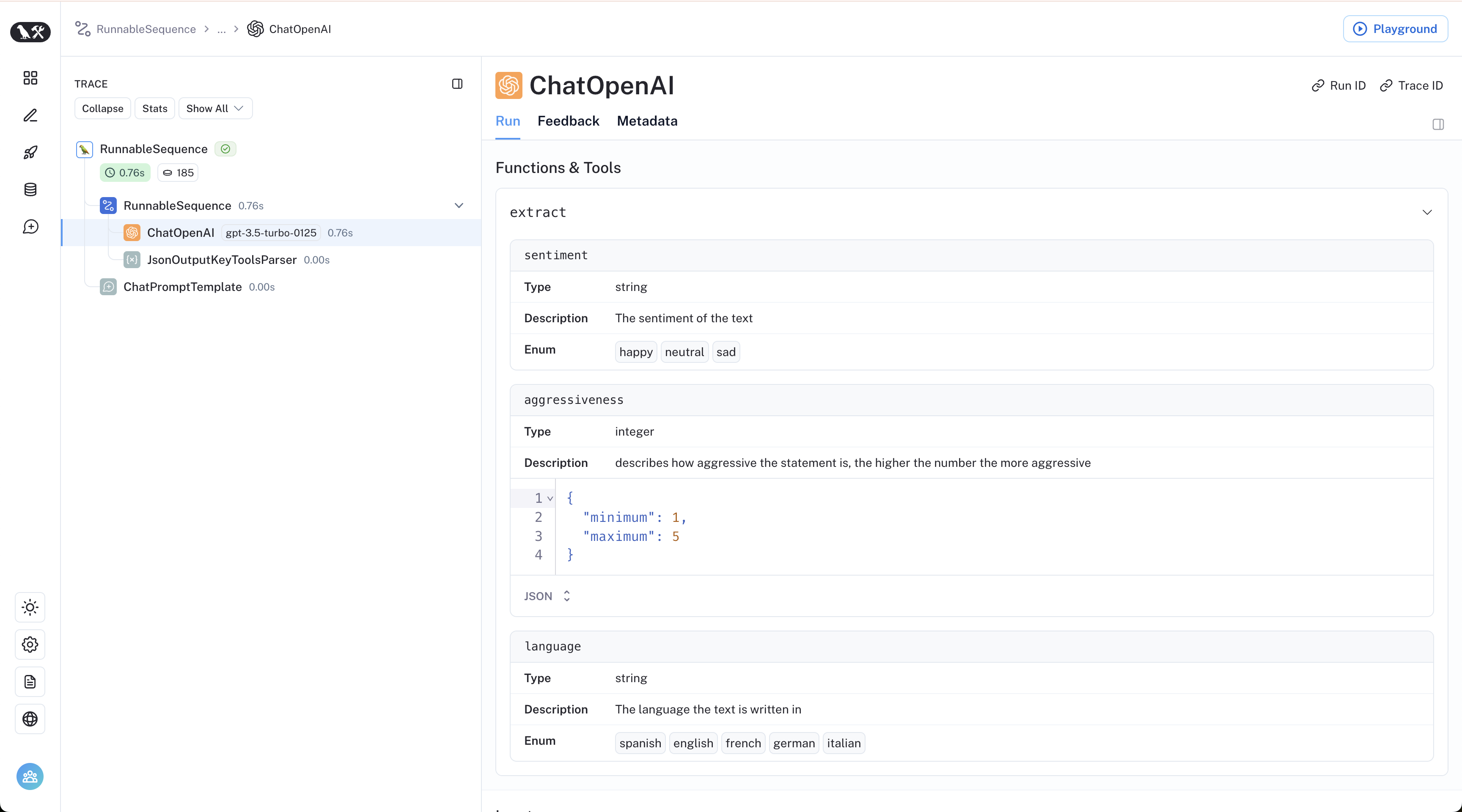
The LangSmith trace lets us peek under the hood: