Build a Retrieval Augmented Generation (RAG) App: Part 2
In many Q&A applications we want to allow the user to have a back-and-forth conversation, meaning the application needs some sort of “memory” of past questions and answers, and some logic for incorporating those into its current thinking.
This is a the second part of a multi-part tutorial:
- Part 1 introduces RAG and walks through a minimal implementation.
- Part 2 (this guide) extends the implementation to accommodate conversation-style interactions and multi-step retrieval processes.
Here we focus on adding logic for incorporating historical messages. This involves the management of a chat history.
We will cover two approaches:
- Chains, in which we execute at most one retrieval step;
- Agents, in which we give an LLM discretion to execute multiple retrieval steps.
The methods presented here leverage tool-calling capabilities in modern chat models. See this page for a table of models supporting tool calling features.
For the external knowledge source, we will use the same LLM Powered Autonomous Agents blog post by Lilian Weng from the Part 1 of the RAG tutorial.
Setup
Components
We will need to select three components from LangChain’s suite of integrations.
A chat model:
Pick your chat model:
- Groq
- OpenAI
- Anthropic
- Google Gemini
- FireworksAI
- MistralAI
- VertexAI
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/groq
yarn add @langchain/groq
pnpm add @langchain/groq
Add environment variables
GROQ_API_KEY=your-api-key
Instantiate the model
import { ChatGroq } from "@langchain/groq";
const llm = new ChatGroq({
model: "llama-3.3-70b-versatile",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/openai
yarn add @langchain/openai
pnpm add @langchain/openai
Add environment variables
OPENAI_API_KEY=your-api-key
Instantiate the model
import { ChatOpenAI } from "@langchain/openai";
const llm = new ChatOpenAI({
model: "gpt-4o-mini",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/anthropic
yarn add @langchain/anthropic
pnpm add @langchain/anthropic
Add environment variables
ANTHROPIC_API_KEY=your-api-key
Instantiate the model
import { ChatAnthropic } from "@langchain/anthropic";
const llm = new ChatAnthropic({
model: "claude-3-5-sonnet-20240620",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/google-genai
yarn add @langchain/google-genai
pnpm add @langchain/google-genai
Add environment variables
GOOGLE_API_KEY=your-api-key
Instantiate the model
import { ChatGoogleGenerativeAI } from "@langchain/google-genai";
const llm = new ChatGoogleGenerativeAI({
model: "gemini-2.0-flash",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/community
yarn add @langchain/community
pnpm add @langchain/community
Add environment variables
FIREWORKS_API_KEY=your-api-key
Instantiate the model
import { ChatFireworks } from "@langchain/community/chat_models/fireworks";
const llm = new ChatFireworks({
model: "accounts/fireworks/models/llama-v3p1-70b-instruct",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/mistralai
yarn add @langchain/mistralai
pnpm add @langchain/mistralai
Add environment variables
MISTRAL_API_KEY=your-api-key
Instantiate the model
import { ChatMistralAI } from "@langchain/mistralai";
const llm = new ChatMistralAI({
model: "mistral-large-latest",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/google-vertexai
yarn add @langchain/google-vertexai
pnpm add @langchain/google-vertexai
Add environment variables
GOOGLE_APPLICATION_CREDENTIALS=credentials.json
Instantiate the model
import { ChatVertexAI } from "@langchain/google-vertexai";
const llm = new ChatVertexAI({
model: "gemini-1.5-flash",
temperature: 0
});
An embedding model:
Pick your embedding model:
- OpenAI
- Azure
- AWS
- VertexAI
- MistralAI
- Cohere
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/openai
yarn add @langchain/openai
pnpm add @langchain/openai
OPENAI_API_KEY=your-api-key
import { OpenAIEmbeddings } from "@langchain/openai";
const embeddings = new OpenAIEmbeddings({
model: "text-embedding-3-large"
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/openai
yarn add @langchain/openai
pnpm add @langchain/openai
AZURE_OPENAI_API_INSTANCE_NAME=<YOUR_INSTANCE_NAME>
AZURE_OPENAI_API_KEY=<YOUR_KEY>
AZURE_OPENAI_API_VERSION="2024-02-01"
import { AzureOpenAIEmbeddings } from "@langchain/openai";
const embeddings = new AzureOpenAIEmbeddings({
azureOpenAIApiEmbeddingsDeploymentName: "text-embedding-ada-002"
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/aws
yarn add @langchain/aws
pnpm add @langchain/aws
BEDROCK_AWS_REGION=your-region
import { BedrockEmbeddings } from "@langchain/aws";
const embeddings = new BedrockEmbeddings({
model: "amazon.titan-embed-text-v1"
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/google-vertexai
yarn add @langchain/google-vertexai
pnpm add @langchain/google-vertexai
GOOGLE_APPLICATION_CREDENTIALS=credentials.json
import { VertexAIEmbeddings } from "@langchain/google-vertexai";
const embeddings = new VertexAIEmbeddings({
model: "text-embedding-004"
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/mistralai
yarn add @langchain/mistralai
pnpm add @langchain/mistralai
MISTRAL_API_KEY=your-api-key
import { MistralAIEmbeddings } from "@langchain/mistralai";
const embeddings = new MistralAIEmbeddings({
model: "mistral-embed"
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/cohere
yarn add @langchain/cohere
pnpm add @langchain/cohere
COHERE_API_KEY=your-api-key
import { CohereEmbeddings } from "@langchain/cohere";
const embeddings = new CohereEmbeddings({
model: "embed-english-v3.0"
});
And a vector store:
Pick your vector store:
- Memory
- Chroma
- FAISS
- MongoDB
- PGVector
- Pinecone
- Qdrant
Install dependencies
- npm
- yarn
- pnpm
npm i langchain
yarn add langchain
pnpm add langchain
import { MemoryVectorStore } from "langchain/vectorstores/memory";
const vectorStore = new MemoryVectorStore(embeddings);
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/community
yarn add @langchain/community
pnpm add @langchain/community
import { Chroma } from "@langchain/community/vectorstores/chroma";
const vectorStore = new Chroma(embeddings, {
collectionName: "a-test-collection",
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/community
yarn add @langchain/community
pnpm add @langchain/community
import { FaissStore } from "@langchain/community/vectorstores/faiss";
const vectorStore = new FaissStore(embeddings, {});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/mongodb
yarn add @langchain/mongodb
pnpm add @langchain/mongodb
import { MongoDBAtlasVectorSearch } from "@langchain/mongodb"
import { MongoClient } from "mongodb";
const client = new MongoClient(process.env.MONGODB_ATLAS_URI || "");
const collection = client
.db(process.env.MONGODB_ATLAS_DB_NAME)
.collection(process.env.MONGODB_ATLAS_COLLECTION_NAME);
const vectorStore = new MongoDBAtlasVectorSearch(embeddings, {
collection: collection,
indexName: "vector_index",
textKey: "text",
embeddingKey: "embedding",
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/community
yarn add @langchain/community
pnpm add @langchain/community
import { PGVectorStore } from "@langchain/community/vectorstores/pgvector";
const vectorStore = await PGVectorStore.initialize(embeddings, {})
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/pinecone
yarn add @langchain/pinecone
pnpm add @langchain/pinecone
import { PineconeStore } from "@langchain/pinecone";
import { Pinecone as PineconeClient } from "@pinecone-database/pinecone";
const pinecone = new PineconeClient();
const vectorStore = new PineconeStore(embeddings, {
pineconeIndex,
maxConcurrency: 5,
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/qdrant
yarn add @langchain/qdrant
pnpm add @langchain/qdrant
import { QdrantVectorStore } from "@langchain/qdrant";
const vectorStore = await QdrantVectorStore.fromExistingCollection(embeddings, {
url: process.env.QDRANT_URL,
collectionName: "langchainjs-testing",
});
Dependencies
In addition, we’ll use the following packages:
- npm
- yarn
- pnpm
npm i langchain @langchain/community @langchain/langgraph cheerio
yarn add langchain @langchain/community @langchain/langgraph cheerio
pnpm add langchain @langchain/community @langchain/langgraph cheerio
LangSmith
Many of the applications you build with LangChain will contain multiple steps with multiple invocations of LLM calls. As these applications get more and more complex, it becomes crucial to be able to inspect what exactly is going on inside your chain or agent. The best way to do this is with LangSmith.
Note that LangSmith is not needed, but it is helpful. If you do want to use LangSmith, after you sign up at the link above, make sure to set your environment variables to start logging traces:
export LANGSMITH_TRACING=true
export LANGSMITH_API_KEY=YOUR_KEY
# Reduce tracing latency if you are not in a serverless environment
# export LANGCHAIN_CALLBACKS_BACKGROUND=true
Chains
Let’s first revisit the vector store we built in Part 1, which indexes an LLM Powered Autonomous Agents blog post by Lilian Weng.
import "cheerio";
import { RecursiveCharacterTextSplitter } from "@langchain/textsplitters";
import { CheerioWebBaseLoader } from "@langchain/community/document_loaders/web/cheerio";
// Load and chunk contents of the blog
const pTagSelector = "p";
const cheerioLoader = new CheerioWebBaseLoader(
"https://lilianweng.github.io/posts/2023-06-23-agent/",
{
selector: pTagSelector,
}
);
const docs = await cheerioLoader.load();
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000,
chunkOverlap: 200,
});
const allSplits = await splitter.splitDocuments(docs);
// Index chunks
await vectorStore.addDocuments(allSplits);
In the Part 1 of the RAG tutorial, we represented the user input, retrieved context, and generated answer as separate keys in the state. Conversational experiences can be naturally represented using a sequence of messages. In addition to messages from the user and assistant, retrieved documents and other artifacts can be incorporated into a message sequence via tool messages. This motivates us to represent the state of our RAG application using a sequence of messages. Specifically, we will have
- User input as a
HumanMessage; - Vector store query as an
AIMessagewith tool calls; - Retrieved documents as a
ToolMessage; - Final response as a
AIMessage.
This model for state is so versatile that LangGraph offers a built-in version for convenience:
import { MessagesAnnotation, StateGraph } from "@langchain/langgraph";
const graph = new StateGraph(MessagesAnnotation);
Leveraging tool-calling to interact with a retrieval step has another benefit, which is that the query for the retrieval is generated by our model. This is especially important in a conversational setting, where user queries may require contextualization based on the chat history. For instance, consider the following exchange:
Human: “What is Task Decomposition?”
AI: “Task decomposition involves breaking down complex tasks into smaller and simpler steps to make them more manageable for an agent or model.”
Human: “What are common ways of doing it?”
In this scenario, a model could generate a query such as
"common approaches to task decomposition". Tool-calling facilitates
this naturally. As in the query
analysis section of the RAG
tutorial, this allows a model to rewrite user queries into more
effective search queries. It also provides support for direct responses
that do not involve a retrieval step (e.g., in response to a generic
greeting from the user).
Let’s turn our retrieval step into a tool:
import { z } from "zod";
import { tool } from "@langchain/core/tools";
const retrieveSchema = z.object({ query: z.string() });
const retrieve = tool(
async ({ query }) => {
const retrievedDocs = await vectorStore.similaritySearch(query, 2);
const serialized = retrievedDocs
.map(
(doc) => `Source: ${doc.metadata.source}\nContent: ${doc.pageContent}`
)
.join("\n");
return [serialized, retrievedDocs];
},
{
name: "retrieve",
description: "Retrieve information related to a query.",
schema: retrieveSchema,
responseFormat: "content_and_artifact",
}
);
See this guide for more detail on creating tools.
Our graph will consist of three nodes:
- A node that fields the user input, either generating a query for the retriever or responding directly;
- A node for the retriever tool that executes the retrieval step;
- A node that generates the final response using the retrieved context.
We build them below. Note that we leverage another pre-built LangGraph
component,
ToolNode,
that executes the tool and adds the result as a ToolMessage to the
state.
import {
AIMessage,
HumanMessage,
SystemMessage,
ToolMessage,
} from "@langchain/core/messages";
import { MessagesAnnotation } from "@langchain/langgraph";
import { ToolNode } from "@langchain/langgraph/prebuilt";
// Step 1: Generate an AIMessage that may include a tool-call to be sent.
async function queryOrRespond(state: typeof MessagesAnnotation.State) {
const llmWithTools = llm.bindTools([retrieve]);
const response = await llmWithTools.invoke(state.messages);
// MessagesState appends messages to state instead of overwriting
return { messages: [response] };
}
// Step 2: Execute the retrieval.
const tools = new ToolNode([retrieve]);
// Step 3: Generate a response using the retrieved content.
async function generate(state: typeof MessagesAnnotation.State) {
// Get generated ToolMessages
let recentToolMessages = [];
for (let i = state["messages"].length - 1; i >= 0; i--) {
let message = state["messages"][i];
if (message instanceof ToolMessage) {
recentToolMessages.push(message);
} else {
break;
}
}
let toolMessages = recentToolMessages.reverse();
// Format into prompt
const docsContent = toolMessages.map((doc) => doc.content).join("\n");
const systemMessageContent =
"You are an assistant for question-answering tasks. " +
"Use the following pieces of retrieved context to answer " +
"the question. If you don't know the answer, say that you " +
"don't know. Use three sentences maximum and keep the " +
"answer concise." +
"\n\n" +
`${docsContent}`;
const conversationMessages = state.messages.filter(
(message) =>
message instanceof HumanMessage ||
message instanceof SystemMessage ||
(message instanceof AIMessage && message.tool_calls.length == 0)
);
const prompt = [
new SystemMessage(systemMessageContent),
...conversationMessages,
];
// Run
const response = await llm.invoke(prompt);
return { messages: [response] };
}
Finally, we compile our application into a single graph object. In
this case, we are just connecting the steps into a sequence. We also
allow the first query_or_respond step to “short-circuit” and respond
directly to the user if it does not generate a tool call. This allows
our application to support conversational experiences– e.g., responding
to generic greetings that may not require a retrieval step
import { StateGraph } from "@langchain/langgraph";
import { toolsCondition } from "@langchain/langgraph/prebuilt";
const graphBuilder = new StateGraph(MessagesAnnotation)
.addNode("queryOrRespond", queryOrRespond)
.addNode("tools", tools)
.addNode("generate", generate)
.addEdge("__start__", "queryOrRespond")
.addConditionalEdges("queryOrRespond", toolsCondition, {
__end__: "__end__",
tools: "tools",
})
.addEdge("tools", "generate")
.addEdge("generate", "__end__");
const graph = graphBuilder.compile();
// Note: tslab only works inside a jupyter notebook. Don't worry about running this code yourself!
import * as tslab from "tslab";
const image = await graph.getGraph().drawMermaidPng();
const arrayBuffer = await image.arrayBuffer();
await tslab.display.png(new Uint8Array(arrayBuffer));
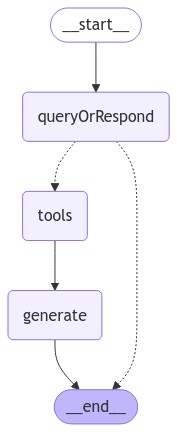
Let’s test our application.
Expand for `prettyPrint` code.
import { BaseMessage, isAIMessage } from "@langchain/core/messages";
const prettyPrint = (message: BaseMessage) => {
let txt = `[${message.getType()}]: ${message.content}`;
if ((isAIMessage(message) && message.tool_calls?.length) || 0 > 0) {
const tool_calls = (message as AIMessage)?.tool_calls
?.map((tc) => `- ${tc.name}(${JSON.stringify(tc.args)})`)
.join("\n");
txt += ` \nTools: \n${tool_calls}`;
}
console.log(txt);
};
Note that it responds appropriately to messages that do not require an additional retrieval step:
let inputs1 = { messages: [{ role: "user", content: "Hello" }] };
for await (const step of await graph.stream(inputs1, {
streamMode: "values",
})) {
const lastMessage = step.messages[step.messages.length - 1];
prettyPrint(lastMessage);
console.log("-----\n");
}
[human]: Hello
-----
[ai]: Hello! How can I assist you today?
-----
And when executing a search, we can stream the steps to observe the query generation, retrieval, and answer generation:
let inputs2 = {
messages: [{ role: "user", content: "What is Task Decomposition?" }],
};
for await (const step of await graph.stream(inputs2, {
streamMode: "values",
})) {
const lastMessage = step.messages[step.messages.length - 1];
prettyPrint(lastMessage);
console.log("-----\n");
}
[human]: What is Task Decomposition?
-----
[ai]:
Tools:
- retrieve({"query":"Task Decomposition"})
-----
[tool]: Source: https://lilianweng.github.io/posts/2023-06-23-agent/
Content: hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.Another quite distinct approach, LLM+P (Liu et al. 2023), involves relying on an external classical planner to do long-horizon planning. This approach utilizes the Planning Domain
Source: https://lilianweng.github.io/posts/2023-06-23-agent/
Content: System message:Think step by step and reason yourself to the right decisions to make sure we get it right.
You will first lay out the names of the core classes, functions, methods that will be necessary, as well as a quick comment on their purpose.Then you will output the content of each file including ALL code.
Each file must strictly follow a markdown code block format, where the following tokens must be replaced such that
FILENAME is the lowercase file name including the file extension,
LANG is the markup code block language for the code’s language, and CODE is the code:FILENAMEYou will start with the “entrypoint” file, then go to the ones that are imported by that file, and so on.
Please note that the code should be fully functional. No placeholders.Follow a language and framework appropriate best practice file naming convention.
Make sure that files contain all imports, types etc. Make sure that code in different files are compatible with each other.
-----
[ai]: Task decomposition is the process of breaking down a complex task into smaller, more manageable steps or subgoals. This can be achieved through various methods, such as using prompts for large language models (LLMs), task-specific instructions, or human inputs. It helps in simplifying the problem-solving process and enhances understanding of the task at hand.
-----
Check out the LangSmith trace here.
Stateful management of chat history
This section of the tutorial previously used the RunnableWithMessageHistory abstraction. You can access that version of the documentation in the v0.2 docs.
As of the v0.3 release of LangChain, we recommend that LangChain users take advantage of LangGraph persistence to incorporate memory into new LangChain applications.
If your code is already relying on RunnableWithMessageHistory or BaseChatMessageHistory, you do not need to make any changes. We do not plan on deprecating this functionality in the near future as it works for simple chat applications and any code that uses RunnableWithMessageHistory will continue to work as expected.
Please see How to migrate to LangGraph Memory for more details.
In production, the Q&A application will usually persist the chat history into a database, and be able to read and update it appropriately.
LangGraph implements a built-in persistence layer, making it ideal for chat applications that support multiple conversational turns.
To manage multiple conversational turns and threads, all we have to do is specify a checkpointer when compiling our application. Because the nodes in our graph are appending messages to the state, we will retain a consistent chat history across invocations.
LangGraph comes with a simple in-memory checkpointer, which we use below. See its documentation for more detail, including how to use different persistence backends (e.g., SQLite or Postgres).
For a detailed walkthrough of how to manage message history, head to the How to add message history (memory) guide.
import { MemorySaver } from "@langchain/langgraph";
const checkpointer = new MemorySaver();
const graphWithMemory = graphBuilder.compile({ checkpointer });
// Specify an ID for the thread
const threadConfig = {
configurable: { thread_id: "abc123" },
streamMode: "values" as const,
};
We can now invoke similar to before:
let inputs3 = {
messages: [{ role: "user", content: "What is Task Decomposition?" }],
};
for await (const step of await graphWithMemory.stream(inputs3, threadConfig)) {
const lastMessage = step.messages[step.messages.length - 1];
prettyPrint(lastMessage);
console.log("-----\n");
}
[human]: What is Task Decomposition?
-----
[ai]:
Tools:
- retrieve({"query":"Task Decomposition"})
-----
[tool]: Source: https://lilianweng.github.io/posts/2023-06-23-agent/
Content: hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.Another quite distinct approach, LLM+P (Liu et al. 2023), involves relying on an external classical planner to do long-horizon planning. This approach utilizes the Planning Domain
Source: https://lilianweng.github.io/posts/2023-06-23-agent/
Content: System message:Think step by step and reason yourself to the right decisions to make sure we get it right.
You will first lay out the names of the core classes, functions, methods that will be necessary, as well as a quick comment on their purpose.Then you will output the content of each file including ALL code.
Each file must strictly follow a markdown code block format, where the following tokens must be replaced such that
FILENAME is the lowercase file name including the file extension,
LANG is the markup code block language for the code’s language, and CODE is the code:FILENAMEYou will start with the “entrypoint” file, then go to the ones that are imported by that file, and so on.
Please note that the code should be fully functional. No placeholders.Follow a language and framework appropriate best practice file naming convention.
Make sure that files contain all imports, types etc. Make sure that code in different files are compatible with each other.
-----
[ai]: Task decomposition is the process of breaking down a complex task into smaller, more manageable steps or subgoals. This can be achieved through various methods, such as using prompts for large language models (LLMs), task-specific instructions, or human inputs. It helps in simplifying the problem-solving process and enhances understanding of the task at hand.
-----
let inputs4 = {
messages: [
{ role: "user", content: "Can you look up some common ways of doing it?" },
],
};
for await (const step of await graphWithMemory.stream(inputs4, threadConfig)) {
const lastMessage = step.messages[step.messages.length - 1];
prettyPrint(lastMessage);
console.log("-----\n");
}
[human]: Can you look up some common ways of doing it?
-----
[ai]:
Tools:
- retrieve({"query":"common methods of task decomposition"})
-----
[tool]: Source: https://lilianweng.github.io/posts/2023-06-23-agent/
Content: hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.Another quite distinct approach, LLM+P (Liu et al. 2023), involves relying on an external classical planner to do long-horizon planning. This approach utilizes the Planning Domain
Source: https://lilianweng.github.io/posts/2023-06-23-agent/
Content: be provided by other developers (as in Plugins) or self-defined (as in function calls).HuggingGPT (Shen et al. 2023) is a framework to use ChatGPT as the task planner to select models available in HuggingFace platform according to the model descriptions and summarize the response based on the execution results.The system comprises of 4 stages:(1) Task planning: LLM works as the brain and parses the user requests into multiple tasks. There are four attributes associated with each task: task type, ID, dependencies, and arguments. They use few-shot examples to guide LLM to do task parsing and planning.Instruction:(2) Model selection: LLM distributes the tasks to expert models, where the request is framed as a multiple-choice question. LLM is presented with a list of models to choose from. Due to the limited context length, task type based filtration is needed.Instruction:(3) Task execution: Expert models execute on the specific tasks and log results.Instruction:(4) Response generation:
-----
[ai]: Common ways of task decomposition include using large language models (LLMs) with simple prompts like "Steps for XYZ" or "What are the subgoals for achieving XYZ?", employing task-specific instructions (e.g., "Write a story outline"), and incorporating human inputs. Additionally, methods like the Tree of Thoughts approach explore multiple reasoning possibilities at each step, creating a structured tree of thoughts. These techniques facilitate breaking down tasks into manageable components for better execution.
-----
Note that the query generated by the model in the second question incorporates the conversational context.
The LangSmith trace is particularly informative here, as we can see exactly what messages are visible to our chat model at each step.
Agents
Agents leverage the reasoning capabilities of LLMs to make decisions during execution. Using agents allows you to offload additional discretion over the retrieval process. Although their behavior is less predictable than the above “chain”, they are able to execute multiple retrieval steps in service of a query, or iterate on a single search.
Below we assemble a minimal RAG agent. Using LangGraph’s pre-built ReAct agent constructor, we can do this in one line.
Check out LangGraph's Agentic RAG tutorial for more advanced formulations.
import { createReactAgent } from "@langchain/langgraph/prebuilt";
const agent = createReactAgent({ llm: llm, tools: [retrieve] });
Let’s inspect the graph:
// Note: tslab only works inside a jupyter notebook. Don't worry about running this code yourself!
import * as tslab from "tslab";
const image = await agent.getGraph().drawMermaidPng();
const arrayBuffer = await image.arrayBuffer();
await tslab.display.png(new Uint8Array(arrayBuffer));

The key difference from our earlier implementation is that instead of a final generation step that ends the run, here the tool invocation loops back to the original LLM call. The model can then either answer the question using the retrieved context, or generate another tool call to obtain more information.
Let’s test this out. We construct a question that would typically require an iterative sequence of retrieval steps to answer:
let inputMessage = `What is the standard method for Task Decomposition?
Once you get the answer, look up common extensions of that method.`;
let inputs5 = { messages: [{ role: "user", content: inputMessage }] };
for await (const step of await agent.stream(inputs5, {
streamMode: "values",
})) {
const lastMessage = step.messages[step.messages.length - 1];
prettyPrint(lastMessage);
console.log("-----\n");
}
[human]: What is the standard method for Task Decomposition?
Once you get the answer, look up common extensions of that method.
-----
[ai]:
Tools:
- retrieve({"query":"standard method for Task Decomposition"})
-----
[tool]: Source: https://lilianweng.github.io/posts/2023-06-23-agent/
Content: hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.Another quite distinct approach, LLM+P (Liu et al. 2023), involves relying on an external classical planner to do long-horizon planning. This approach utilizes the Planning Domain
Source: https://lilianweng.github.io/posts/2023-06-23-agent/
Content: System message:Think step by step and reason yourself to the right decisions to make sure we get it right.
You will first lay out the names of the core classes, functions, methods that will be necessary, as well as a quick comment on their purpose.Then you will output the content of each file including ALL code.
Each file must strictly follow a markdown code block format, where the following tokens must be replaced such that
FILENAME is the lowercase file name including the file extension,
LANG is the markup code block language for the code’s language, and CODE is the code:FILENAMEYou will start with the “entrypoint” file, then go to the ones that are imported by that file, and so on.
Please note that the code should be fully functional. No placeholders.Follow a language and framework appropriate best practice file naming convention.
Make sure that files contain all imports, types etc. Make sure that code in different files are compatible with each other.
-----
[ai]:
Tools:
- retrieve({"query":"common extensions of Task Decomposition method"})
-----
[tool]: Source: https://lilianweng.github.io/posts/2023-06-23-agent/
Content: hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.Another quite distinct approach, LLM+P (Liu et al. 2023), involves relying on an external classical planner to do long-horizon planning. This approach utilizes the Planning Domain
Source: https://lilianweng.github.io/posts/2023-06-23-agent/
Content: be provided by other developers (as in Plugins) or self-defined (as in function calls).HuggingGPT (Shen et al. 2023) is a framework to use ChatGPT as the task planner to select models available in HuggingFace platform according to the model descriptions and summarize the response based on the execution results.The system comprises of 4 stages:(1) Task planning: LLM works as the brain and parses the user requests into multiple tasks. There are four attributes associated with each task: task type, ID, dependencies, and arguments. They use few-shot examples to guide LLM to do task parsing and planning.Instruction:(2) Model selection: LLM distributes the tasks to expert models, where the request is framed as a multiple-choice question. LLM is presented with a list of models to choose from. Due to the limited context length, task type based filtration is needed.Instruction:(3) Task execution: Expert models execute on the specific tasks and log results.Instruction:(4) Response generation:
-----
[ai]: ### Standard Method for Task Decomposition
The standard method for task decomposition involves breaking down hard tasks into smaller, more manageable steps. This can be achieved through various approaches:
1. **Chain of Thought (CoT)**: This method transforms large tasks into multiple manageable tasks, providing insight into the model's reasoning process.
2. **Prompting**: Using simple prompts like "Steps for XYZ" or "What are the subgoals for achieving XYZ?" to guide the decomposition.
3. **Task-Specific Instructions**: Providing specific instructions tailored to the task, such as "Write a story outline" for writing a novel.
4. **Human Inputs**: Involving human input to assist in the decomposition process.
### Common Extensions of Task Decomposition
Several extensions have been developed to enhance the task decomposition process:
1. **Tree of Thoughts (ToT)**: This method extends CoT by exploring multiple reasoning possibilities at each step. It decomposes the problem into multiple thought steps and generates various thoughts per step, creating a tree structure. The search process can utilize either breadth-first search (BFS) or depth-first search (DFS), with each state evaluated by a classifier or through majority voting.
2. **LLM+P**: This approach involves using an external classical planner for long-horizon planning, integrating planning domains to enhance the decomposition process.
3. **HuggingGPT**: This framework utilizes ChatGPT as a task planner to select models from the HuggingFace platform based on model descriptions. It consists of four stages:
- **Task Planning**: Parsing user requests into multiple tasks with attributes like task type, ID, dependencies, and arguments.
- **Model Selection**: Distributing tasks to expert models based on a multiple-choice question format.
- **Task Execution**: Expert models execute specific tasks and log results.
- **Response Generation**: Compiling the results into a coherent response.
These extensions aim to improve the efficiency and effectiveness of task decomposition, making it easier to manage complex tasks.
-----
Note that the agent:
- Generates a query to search for a standard method for task decomposition;
- Receiving the answer, generates a second query to search for common extensions of it;
- Having received all necessary context, answers the question.
We can see the full sequence of steps, along with latency and other metadata, in the LangSmith trace.
Next steps
We’ve covered the steps to build a basic conversational Q&A application:
- We used chains to build a predictable application that generates at most one query per user input;
- We used agents to build an application that can iterate on a sequence of queries.
To explore different types of retrievers and retrieval strategies, visit the retrievers section of the how-to guides.
For a detailed walkthrough of LangChain’s conversation memory abstractions, visit the How to add message history (memory) guide.
To learn more about agents, check out the conceptual guide and LangGraph agent architectures page.