Build a Question/Answering system over SQL data
This guide assumes familiarity with the following concepts:
Enabling a LLM system to query structured data can be qualitatively different from unstructured text data. Whereas in the latter it is common to generate text that can be searched against a vector database, the approach for structured data is often for the LLM to write and execute queries in a DSL, such as SQL. In this guide we’ll go over the basic ways to create a Q&A system over tabular data in databases. We will cover implementations using both chains and agents. These systems will allow us to ask a question about the data in a database and get back a natural language answer. The main difference between the two is that our agent can query the database in a loop as many times as it needs to answer the question.
⚠️ Security note ⚠️
Building Q&A systems of SQL databases requires executing model-generated SQL queries. There are inherent risks in doing this. Make sure that your database connection permissions are always scoped as narrowly as possible for your chain/agent’s needs. This will mitigate though not eliminate the risks of building a model-driven system. For more on general security best practices, see here.
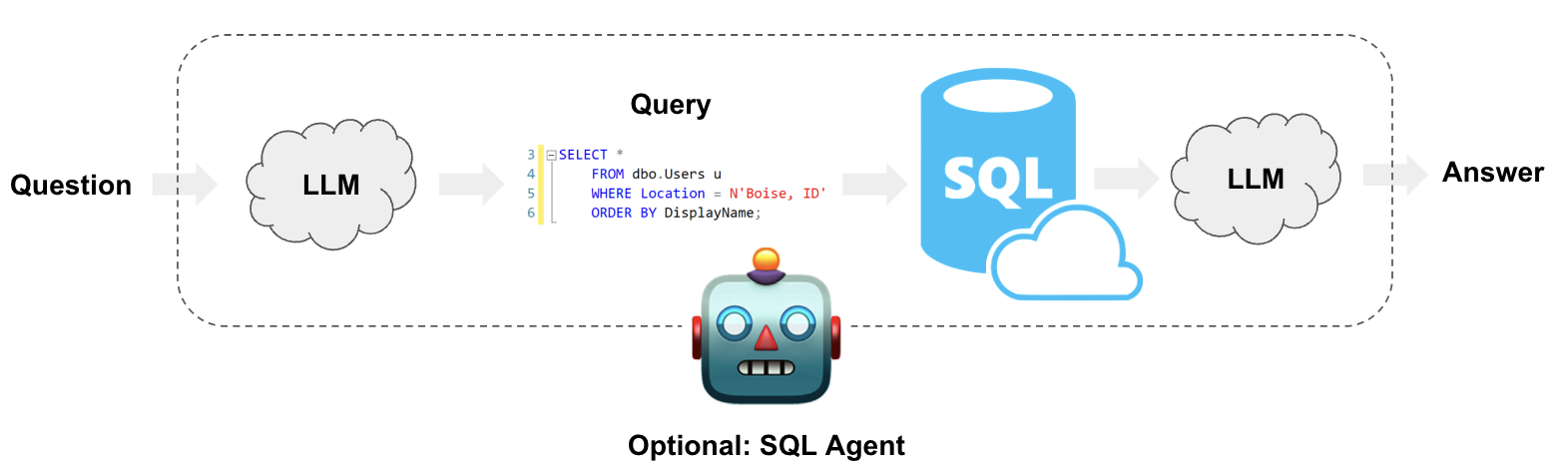
Architecture
At a high-level, the steps of these systems are:
- Convert question to SQL query: Model converts user input to a SQL query.
- Execute SQL query: Execute the query.
- Answer the question: Model responds to user input using the query results.
Setup
First, get required packages and set environment variables:
bash npm2yarn npm i langchain @langchain/community @langchain/langgraph
# Uncomment the below to use LangSmith. Not required, but recommended for debugging and observability.
# export LANGSMITH_API_KEY=<your key>
# export LANGSMITH_TRACING=true
# Reduce tracing latency if you are not in a serverless environment
# export LANGCHAIN_CALLBACKS_BACKGROUND=true
Sample data
The below example will use a SQLite connection with the Chinook
database, which is a sample database that represents a digital media
store. Follow these installation
steps to create
Chinook.db in the same directory as this notebook. You can also
download and build the database via the command line:
curl -s https://raw.githubusercontent.com/lerocha/chinook-database/master/ChinookDatabase/DataSources/Chinook_Sqlite.sql | sqlite3 Chinook.db
Now, Chinook.db is in our directory and we can interface with it using
the
SqlDatabase
class:
import { SqlDatabase } from "langchain/sql_db";
import { DataSource } from "typeorm";
const datasource = new DataSource({
type: "sqlite",
database: "Chinook.db",
});
const db = await SqlDatabase.fromDataSourceParams({
appDataSource: datasource,
});
await db.run("SELECT * FROM Artist LIMIT 10;");
[{"ArtistId":1,"Name":"AC/DC"},{"ArtistId":2,"Name":"Accept"},{"ArtistId":3,"Name":"Aerosmith"},{"ArtistId":4,"Name":"Alanis Morissette"},{"ArtistId":5,"Name":"Alice In Chains"},{"ArtistId":6,"Name":"Antônio Carlos Jobim"},{"ArtistId":7,"Name":"Apocalyptica"},{"ArtistId":8,"Name":"Audioslave"},{"ArtistId":9,"Name":"BackBeat"},{"ArtistId":10,"Name":"Billy Cobham"}]
Great! We’ve got a SQL database that we can query. Now let’s try hooking it up to an LLM.
Chains
Chains are compositions of predictable steps. In LangGraph, we can represent a chain via simple sequence of nodes. Let’s create a sequence of steps that, given a question, does the following: - converts the question into a SQL query; - executes the query; - uses the result to answer the original question.
There are scenarios not supported by this arrangement. For example, this system will execute a SQL query for any user input– even “hello”. Importantly, as we’ll see below, some questions require more than one query to answer. We will address these scenarios in the Agents section.
Application state
The LangGraph state of our application controls what data is input to the application, transferred between steps, and output by the application.
For this application, we can just keep track of the input question, generated query, query result, and generated answer:
import { Annotation } from "@langchain/langgraph";
const InputStateAnnotation = Annotation.Root({
question: Annotation<string>,
});
const StateAnnotation = Annotation.Root({
question: Annotation<string>,
query: Annotation<string>,
result: Annotation<string>,
answer: Annotation<string>,
});
Now we just need functions that operate on this state and populate its contents.
Convert question to SQL query
The first step is to take the user input and convert it to a SQL query. To reliably obtain SQL queries (absent markdown formatting and explanations or clarifications), we will make use of LangChain’s structured output abstraction.
Let’s select a chat model for our application:
Pick your chat model:
- Groq
- OpenAI
- Anthropic
- Google Gemini
- FireworksAI
- MistralAI
- VertexAI
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/groq
yarn add @langchain/groq
pnpm add @langchain/groq
Add environment variables
GROQ_API_KEY=your-api-key
Instantiate the model
import { ChatGroq } from "@langchain/groq";
const llm = new ChatGroq({
model: "llama-3.3-70b-versatile",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/openai
yarn add @langchain/openai
pnpm add @langchain/openai
Add environment variables
OPENAI_API_KEY=your-api-key
Instantiate the model
import { ChatOpenAI } from "@langchain/openai";
const llm = new ChatOpenAI({
model: "gpt-4o-mini",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/anthropic
yarn add @langchain/anthropic
pnpm add @langchain/anthropic
Add environment variables
ANTHROPIC_API_KEY=your-api-key
Instantiate the model
import { ChatAnthropic } from "@langchain/anthropic";
const llm = new ChatAnthropic({
model: "claude-3-5-sonnet-20240620",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/google-genai
yarn add @langchain/google-genai
pnpm add @langchain/google-genai
Add environment variables
GOOGLE_API_KEY=your-api-key
Instantiate the model
import { ChatGoogleGenerativeAI } from "@langchain/google-genai";
const llm = new ChatGoogleGenerativeAI({
model: "gemini-2.0-flash",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/community
yarn add @langchain/community
pnpm add @langchain/community
Add environment variables
FIREWORKS_API_KEY=your-api-key
Instantiate the model
import { ChatFireworks } from "@langchain/community/chat_models/fireworks";
const llm = new ChatFireworks({
model: "accounts/fireworks/models/llama-v3p1-70b-instruct",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/mistralai
yarn add @langchain/mistralai
pnpm add @langchain/mistralai
Add environment variables
MISTRAL_API_KEY=your-api-key
Instantiate the model
import { ChatMistralAI } from "@langchain/mistralai";
const llm = new ChatMistralAI({
model: "mistral-large-latest",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/google-vertexai
yarn add @langchain/google-vertexai
pnpm add @langchain/google-vertexai
Add environment variables
GOOGLE_APPLICATION_CREDENTIALS=credentials.json
Instantiate the model
import { ChatVertexAI } from "@langchain/google-vertexai";
const llm = new ChatVertexAI({
model: "gemini-1.5-flash",
temperature: 0
});
We will pull a prompt from the Prompt Hub to instruct the model.
import { pull } from "langchain/hub";
import { ChatPromptTemplate } from "@langchain/core/prompts";
const queryPromptTemplate = await pull<ChatPromptTemplate>(
"langchain-ai/sql-query-system-prompt"
);
queryPromptTemplate.promptMessages.forEach((message) => {
console.log(message.lc_kwargs.prompt.template);
});
Given an input question, create a syntactically correct {dialect} query to run to help find the answer. Unless the user specifies in his question a specific number of examples they wish to obtain, always limit your query to at most {top_k} results. You can order the results by a relevant column to return the most interesting examples in the database.
Never query for all the columns from a specific table, only ask for a the few relevant columns given the question.
Pay attention to use only the column names that you can see in the schema description. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table.
Only use the following tables:
{table_info}
Question: {input}
The prompt includes several parameters we will need to populate, such as
the SQL dialect and table schemas. LangChain’s
SqlDatabase
object includes methods to help with this. Our writeQuery step will
just populate these parameters and prompt a model to generate the SQL
query:
import { z } from "zod";
const queryOutput = z.object({
query: z.string().describe("Syntactically valid SQL query."),
});
const structuredLlm = llm.withStructuredOutput(queryOutput);
const writeQuery = async (state: typeof InputStateAnnotation.State) => {
const promptValue = await queryPromptTemplate.invoke({
dialect: db.appDataSourceOptions.type,
top_k: 10,
table_info: await db.getTableInfo(),
input: state.question,
});
const result = await structuredLlm.invoke(promptValue);
return { query: result.query };
};
Let’s test it out:
await writeQuery({ question: "How many Employees are there?" });
{ query: 'SELECT COUNT(*) AS EmployeeCount FROM Employee;' }
Execute query
This is the most dangerous part of creating a SQL chain. Consider carefully if it is OK to run automated queries over your data. Minimize the database connection permissions as much as possible. Consider adding a human approval step to you chains before query execution (see below).
To execute the query, we will load a tool from
langchain-community.
Our executeQuery node will just wrap this tool:
import { QuerySqlTool } from "langchain/tools/sql";
const executeQuery = async (state: typeof StateAnnotation.State) => {
const executeQueryTool = new QuerySqlTool(db);
return { result: await executeQueryTool.invoke(state.query) };
};
Testing this step:
await executeQuery({
question: "",
query: "SELECT COUNT(*) AS EmployeeCount FROM Employee;",
result: "",
answer: "",
});
{ result: '[{"EmployeeCount":8}]' }
Generate answer
Finally, our last step generates an answer to the question given the information pulled from the database:
const generateAnswer = async (state: typeof StateAnnotation.State) => {
const promptValue =
"Given the following user question, corresponding SQL query, " +
"and SQL result, answer the user question.\n\n" +
`Question: ${state.question}\n` +
`SQL Query: ${state.query}\n` +
`SQL Result: ${state.result}\n`;
const response = await llm.invoke(promptValue);
return { answer: response.content };
};
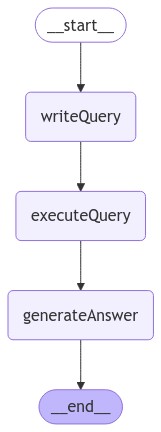
Orchestrating with LangGraph
Finally, we compile our application into a single graph object. In
this case, we are just connecting the three steps into a single
sequence.
import { StateGraph } from "@langchain/langgraph";
const graphBuilder = new StateGraph({
stateSchema: StateAnnotation,
})
.addNode("writeQuery", writeQuery)
.addNode("executeQuery", executeQuery)
.addNode("generateAnswer", generateAnswer)
.addEdge("__start__", "writeQuery")
.addEdge("writeQuery", "executeQuery")
.addEdge("executeQuery", "generateAnswer")
.addEdge("generateAnswer", "__end__");
const graph = graphBuilder.compile();
LangGraph also comes with built-in utilities for visualizing the control flow of your application:
// Note: tslab only works inside a jupyter notebook. Don't worry about running this code yourself!
import * as tslab from "tslab";
const image = await graph.getGraph().drawMermaidPng();
const arrayBuffer = await image.arrayBuffer();
await tslab.display.png(new Uint8Array(arrayBuffer));
Let’s test our application! Note that we can stream the results of individual steps:
let inputs = { question: "How many employees are there?" };
console.log(inputs);
console.log("\n====\n");
for await (const step of await graph.stream(inputs, {
streamMode: "updates",
})) {
console.log(step);
console.log("\n====\n");
}
{ question: 'How many employees are there?' }
====
{
writeQuery: { query: 'SELECT COUNT(*) AS EmployeeCount FROM Employee;' }
}
====
{ executeQuery: { result: '[{"EmployeeCount":8}]' } }
====
{ generateAnswer: { answer: 'There are 8 employees.' } }
====
Check out the LangSmith trace.
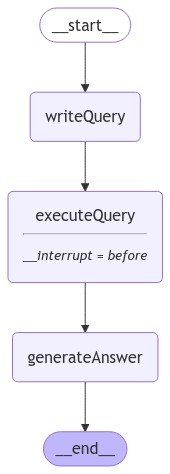
Human-in-the-loop
LangGraph supports a number of features that can be useful for this workflow. One of them is human-in-the-loop: we can interrupt our application before sensitive steps (such as the execution of a SQL query) for human review. This is enabled by LangGraph’s persistence layer, which saves run progress to your storage of choice. Below, we specify storage in-memory:
import { MemorySaver } from "@langchain/langgraph";
const checkpointer = new MemorySaver();
const graphWithInterrupt = graphBuilder.compile({
checkpointer: checkpointer,
interruptBefore: ["executeQuery"],
});
// Now that we're using persistence, we need to specify a thread ID
// so that we can continue the run after review.
const threadConfig = {
configurable: { thread_id: "1" },
streamMode: "updates" as const,
};
const image = await graphWithInterrupt.getGraph().drawMermaidPng();
const arrayBuffer = await image.arrayBuffer();
await tslab.display.png(new Uint8Array(arrayBuffer));
Let’s repeat the same run, adding in a simple yes/no approval step:
console.log(inputs);
console.log("\n====\n");
for await (const step of await graphWithInterrupt.stream(
inputs,
threadConfig
)) {
console.log(step);
console.log("\n====\n");
}
// Will log when the graph is interrupted, after `executeQuery`.
console.log("---GRAPH INTERRUPTED---");
{ question: 'How many employees are there?' }
====
{
writeQuery: { query: 'SELECT COUNT(*) AS EmployeeCount FROM Employee;' }
}
====
---GRAPH INTERRUPTED---
The run interrupts before the query is executed. At this point, our application can handle an interaction with a user, who reviews the query.
If approved, running the same thread with a null input will continue
from where we left off. This is enabled by LangGraph’s
persistence
layer.
for await (const step of await graphWithInterrupt.stream(null, threadConfig)) {
console.log(step);
console.log("\n====\n");
}
{ executeQuery: { result: '[{"EmployeeCount":8}]' } }
====
{ generateAnswer: { answer: 'There are 8 employees.' } }
====
See this LangGraph guide for more detail and examples.
Next steps
For more complex query-generation, we may want to create few-shot prompts or add query-checking steps. For advanced techniques like this and more check out:
- Prompting strategies: Advanced prompt engineering techniques.
- Query checking: Add query validation and error handling.
- Large databases: Techniques for working with large databases.
Agents
Agents leverage the reasoning capabilities of LLMs to make decisions during execution. Using agents allows you to offload additional discretion over the query generation and execution process. Although their behavior is less predictable than the above “chain”, they feature some advantages:
- They can query the database as many times as needed to answer the user question.
- They can recover from errors by running a generated query, catching the traceback and regenerating it correctly.
- They can answer questions based on the databases’ schema as well as on the databases’ content (like describing a specific table).
Below we assemble a minimal SQL agent. We will equip it with a set of tools using LangChain’s SqlToolkit. Using LangGraph’s pre-built ReAct agent constructor, we can do this in one line.
The SqlToolkit includes tools that can:
- Create and execute queries
- Check query syntax
- Retrieve table descriptions
- … and more
import { SqlToolkit } from "langchain/agents/toolkits/sql";
const toolkit = new SqlToolkit(db, llm);
const tools = toolkit.getTools();
console.log(
tools.map((tool) => ({
name: tool.name,
description: tool.description,
}))
);
[
{
name: 'query-sql',
description: 'Input to this tool is a detailed and correct SQL query, output is a result from the database.\n' +
' If the query is not correct, an error message will be returned.\n' +
' If an error is returned, rewrite the query, check the query, and try again.'
},
{
name: 'info-sql',
description: 'Input to this tool is a comma-separated list of tables, output is the schema and sample rows for those tables.\n' +
' Be sure that the tables actually exist by calling list-tables-sql first!\n' +
'\n' +
' Example Input: "table1, table2, table3.'
},
{
name: 'list-tables-sql',
description: 'Input is an empty string, output is a comma-separated list of tables in the database.'
},
{
name: 'query-checker',
description: 'Use this tool to double check if your query is correct before executing it.\n' +
' Always use this tool before executing a query with query-sql!'
}
]
System Prompt
We will also want to load a system prompt for our agent. This will consist of instructions for how to behave.
import { pull } from "langchain/hub";
import { ChatPromptTemplate } from "@langchain/core/prompts";
const systemPromptTemplate = await pull<ChatPromptTemplate>(
"langchain-ai/sql-agent-system-prompt"
);
console.log(systemPromptTemplate.promptMessages[0].lc_kwargs.prompt.template);
You are an agent designed to interact with a SQL database.
Given an input question, create a syntactically correct {dialect} query to run, then look at the results of the query and return the answer.
Unless the user specifies a specific number of examples they wish to obtain, always limit your query to at most {top_k} results.
You can order the results by a relevant column to return the most interesting examples in the database.
Never query for all the columns from a specific table, only ask for the relevant columns given the question.
You have access to tools for interacting with the database.
Only use the below tools. Only use the information returned by the below tools to construct your final answer.
You MUST double check your query before executing it. If you get an error while executing a query, rewrite the query and try again.
DO NOT make any DML statements (INSERT, UPDATE, DELETE, DROP etc.) to the database.
To start you should ALWAYS look at the tables in the database to see what you can query.
Do NOT skip this step.
Then you should query the schema of the most relevant tables.
Let’s populate the parameters highlighted in the prompt:
const systemMessage = await systemPromptTemplate.format({
dialect: "SQLite",
top_k: 5,
});
Initializing agent
We will use a prebuilt LangGraph agent to build our agent
import { createReactAgent } from "@langchain/langgraph/prebuilt";
const agent = createReactAgent({
llm: llm,
tools: tools,
prompt: systemMessage,
});
Consider how the agent responds to the below question:
Expand for `prettyPrint` code.
import { AIMessage, BaseMessage, isAIMessage } from "@langchain/core/messages";
const prettyPrint = (message: BaseMessage) => {
let txt = `[${message._getType()}]: ${message.content}`;
if ((isAIMessage(message) && message.tool_calls?.length) || 0 > 0) {
const tool_calls = (message as AIMessage)?.tool_calls
?.map((tc) => `- ${tc.name}(${JSON.stringify(tc.args)})`)
.join("\n");
txt += ` \nTools: \n${tool_calls}`;
}
console.log(txt);
};
let inputs2 = {
messages: [
{ role: "user", content: "Which country's customers spent the most?" },
],
};
for await (const step of await agent.stream(inputs2, {
streamMode: "values",
})) {
const lastMessage = step.messages[step.messages.length - 1];
prettyPrint(lastMessage);
console.log("-----\n");
}
[human]: Which country's customers spent the most?
-----
[ai]:
Tools:
- list-tables-sql({"input":""})
-----
[tool]: Album, Artist, Customer, Employee, Genre, Invoice, InvoiceLine, MediaType, Playlist, PlaylistTrack, Track
-----
[ai]:
Tools:
- info-sql({"input":"Customer, Invoice, InvoiceLine"})
- info-sql({"input":"Invoice"})
-----
[tool]: CREATE TABLE Invoice (
InvoiceId INTEGER NOT NULL, CustomerId INTEGER NOT NULL, InvoiceDate DATETIME NOT NULL, BillingAddress NVARCHAR(70) , BillingCity NVARCHAR(40) , BillingState NVARCHAR(40) , BillingCountry NVARCHAR(40) , BillingPostalCode NVARCHAR(10) , Total NUMERIC(10,2) NOT NULL)
SELECT * FROM "Invoice" LIMIT 3;
InvoiceId CustomerId InvoiceDate BillingAddress BillingCity BillingState BillingCountry BillingPostalCode Total
1 2 2021-01-01 00:00:00 Theodor-Heuss-Straße 34 Stuttgart null Germany 70174 1.98
2 4 2021-01-02 00:00:00 Ullevålsveien 14 Oslo null Norway 0171 3.96
3 8 2021-01-03 00:00:00 Grétrystraat 63 Brussels null Belgium 1000 5.94
-----
[ai]:
Tools:
- query-checker({"input":"SELECT c.Country, SUM(i.Total) AS TotalSpent \nFROM Customer c \nJOIN Invoice i ON c.CustomerId = i.CustomerId \nGROUP BY c.Country \nORDER BY TotalSpent DESC \nLIMIT 5;"})
-----
[tool]: The SQL query you provided appears to be correct and does not contain any of the common mistakes listed. It properly joins the `Customer` and `Invoice` tables, groups the results by country, and orders the total spending in descending order while limiting the results to the top 5 countries.
Here is the original query reproduced:
```sql
SELECT c.Country, SUM(i.Total) AS TotalSpent
FROM Customer c
JOIN Invoice i ON c.CustomerId = i.CustomerId
GROUP BY c.Country
ORDER BY TotalSpent DESC
LIMIT 5;
```
No changes are necessary.
-----
[ai]:
Tools:
- query-sql({"input":"SELECT c.Country, SUM(i.Total) AS TotalSpent \nFROM Customer c \nJOIN Invoice i ON c.CustomerId = i.CustomerId \nGROUP BY c.Country \nORDER BY TotalSpent DESC \nLIMIT 5;"})
-----
[tool]: [{"Country":"USA","TotalSpent":523.0600000000003},{"Country":"Canada","TotalSpent":303.9599999999999},{"Country":"France","TotalSpent":195.09999999999994},{"Country":"Brazil","TotalSpent":190.09999999999997},{"Country":"Germany","TotalSpent":156.48}]
-----
[ai]: The countries whose customers spent the most are:
1. **USA** - $523.06
2. **Canada** - $303.96
3. **France** - $195.10
4. **Brazil** - $190.10
5. **Germany** - $156.48
-----
You can also use the LangSmith trace to visualize these steps and associated metadata.
Note that the agent executes multiple queries until it has the information it needs: 1. List available tables; 2. Retrieves the schema for three tables; 3. Queries multiple of the tables via a join operation.
The agent is then able to use the result of the final query to generate an answer to the original question.
The agent can similarly handle qualitative questions:
let inputs3 = {
messages: [{ role: "user", content: "Describe the playlisttrack table" }],
};
for await (const step of await agent.stream(inputs3, {
streamMode: "values",
})) {
const lastMessage = step.messages[step.messages.length - 1];
prettyPrint(lastMessage);
console.log("-----\n");
}
[human]: Describe the playlisttrack table
-----
[ai]:
Tools:
- list-tables-sql({"input":""})
-----
[tool]: Album, Artist, Customer, Employee, Genre, Invoice, InvoiceLine, MediaType, Playlist, PlaylistTrack, Track
-----
[ai]:
Tools:
- info-sql({"input":"PlaylistTrack"})
-----
[tool]: CREATE TABLE PlaylistTrack (
PlaylistId INTEGER NOT NULL, TrackId INTEGER NOT NULL)
SELECT * FROM "PlaylistTrack" LIMIT 3;
PlaylistId TrackId
1 3402
1 3389
1 3390
-----
[ai]: The `PlaylistTrack` table has the following schema:
- **PlaylistId**: INTEGER (NOT NULL)
- **TrackId**: INTEGER (NOT NULL)
This table is used to associate tracks with playlists. Here are some sample rows from the table:
| PlaylistId | TrackId |
|------------|---------|
| 1 | 3402 |
| 1 | 3389 |
| 1 | 3390 |
-----
Dealing with high-cardinality columns
In order to filter columns that contain proper nouns such as addresses, song names or artists, we first need to double-check the spelling in order to filter the data correctly.
We can achieve this by creating a vector store with all the distinct proper nouns that exist in the database. We can then have the agent query that vector store each time the user includes a proper noun in their question, to find the correct spelling for that word. In this way, the agent can make sure it understands which entity the user is referring to before building the target query.
First we need the unique values for each entity we want, for which we define a function that parses the result into a list of elements:
async function queryAsList(
database: SqlDatabase,
query: string
): Promise<string[]> {
const res: Array<{ [key: string]: string }> = JSON.parse(
await database.run(query)
)
.flat()
.filter((el: { [key: string]: string } | null) => el != null);
const justValues: Array<string> = res.map((item) =>
Object.values(item)[0]
.replace(/\b\d+\b/g, "")
.trim()
);
return justValues;
}
// Gather entities into a list
let artists: string[] = await queryAsList(db, "SELECT Name FROM Artist");
let albums: string[] = await queryAsList(db, "SELECT Title FROM Album");
let properNouns = artists.concat(albums);
console.log(`Total: ${properNouns.length}\n`);
console.log(`Sample: ${properNouns.slice(0, 5)}...`);
Total: 622
Sample: AC/DC,Accept,Aerosmith,Alanis Morissette,Alice In Chains...
Using this function, we can create a retriever tool that the agent can execute at its discretion.
Let’s select an embeddings model and vector store for this step:
Pick your embedding model:
- OpenAI
- Azure
- AWS
- VertexAI
- MistralAI
- Cohere
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/openai
yarn add @langchain/openai
pnpm add @langchain/openai
OPENAI_API_KEY=your-api-key
import { OpenAIEmbeddings } from "@langchain/openai";
const embeddings = new OpenAIEmbeddings({
model: "text-embedding-3-large"
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/openai
yarn add @langchain/openai
pnpm add @langchain/openai
AZURE_OPENAI_API_INSTANCE_NAME=<YOUR_INSTANCE_NAME>
AZURE_OPENAI_API_KEY=<YOUR_KEY>
AZURE_OPENAI_API_VERSION="2024-02-01"
import { AzureOpenAIEmbeddings } from "@langchain/openai";
const embeddings = new AzureOpenAIEmbeddings({
azureOpenAIApiEmbeddingsDeploymentName: "text-embedding-ada-002"
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/aws
yarn add @langchain/aws
pnpm add @langchain/aws
BEDROCK_AWS_REGION=your-region
import { BedrockEmbeddings } from "@langchain/aws";
const embeddings = new BedrockEmbeddings({
model: "amazon.titan-embed-text-v1"
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/google-vertexai
yarn add @langchain/google-vertexai
pnpm add @langchain/google-vertexai
GOOGLE_APPLICATION_CREDENTIALS=credentials.json
import { VertexAIEmbeddings } from "@langchain/google-vertexai";
const embeddings = new VertexAIEmbeddings({
model: "text-embedding-004"
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/mistralai
yarn add @langchain/mistralai
pnpm add @langchain/mistralai
MISTRAL_API_KEY=your-api-key
import { MistralAIEmbeddings } from "@langchain/mistralai";
const embeddings = new MistralAIEmbeddings({
model: "mistral-embed"
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/cohere
yarn add @langchain/cohere
pnpm add @langchain/cohere
COHERE_API_KEY=your-api-key
import { CohereEmbeddings } from "@langchain/cohere";
const embeddings = new CohereEmbeddings({
model: "embed-english-v3.0"
});
Pick your vector store:
- Memory
- Chroma
- FAISS
- MongoDB
- PGVector
- Pinecone
- Qdrant
Install dependencies
- npm
- yarn
- pnpm
npm i langchain
yarn add langchain
pnpm add langchain
import { MemoryVectorStore } from "langchain/vectorstores/memory";
const vectorStore = new MemoryVectorStore(embeddings);
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/community
yarn add @langchain/community
pnpm add @langchain/community
import { Chroma } from "@langchain/community/vectorstores/chroma";
const vectorStore = new Chroma(embeddings, {
collectionName: "a-test-collection",
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/community
yarn add @langchain/community
pnpm add @langchain/community
import { FaissStore } from "@langchain/community/vectorstores/faiss";
const vectorStore = new FaissStore(embeddings, {});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/mongodb
yarn add @langchain/mongodb
pnpm add @langchain/mongodb
import { MongoDBAtlasVectorSearch } from "@langchain/mongodb"
import { MongoClient } from "mongodb";
const client = new MongoClient(process.env.MONGODB_ATLAS_URI || "");
const collection = client
.db(process.env.MONGODB_ATLAS_DB_NAME)
.collection(process.env.MONGODB_ATLAS_COLLECTION_NAME);
const vectorStore = new MongoDBAtlasVectorSearch(embeddings, {
collection: collection,
indexName: "vector_index",
textKey: "text",
embeddingKey: "embedding",
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/community
yarn add @langchain/community
pnpm add @langchain/community
import { PGVectorStore } from "@langchain/community/vectorstores/pgvector";
const vectorStore = await PGVectorStore.initialize(embeddings, {})
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/pinecone
yarn add @langchain/pinecone
pnpm add @langchain/pinecone
import { PineconeStore } from "@langchain/pinecone";
import { Pinecone as PineconeClient } from "@pinecone-database/pinecone";
const pinecone = new PineconeClient();
const vectorStore = new PineconeStore(embeddings, {
pineconeIndex,
maxConcurrency: 5,
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/qdrant
yarn add @langchain/qdrant
pnpm add @langchain/qdrant
import { QdrantVectorStore } from "@langchain/qdrant";
const vectorStore = await QdrantVectorStore.fromExistingCollection(embeddings, {
url: process.env.QDRANT_URL,
collectionName: "langchainjs-testing",
});
We can now construct a retrieval tool that can search over relevant proper nouns in the database:
import { createRetrieverTool } from "langchain/tools/retriever";
import { Document } from "@langchain/core/documents";
const documents = properNouns.map(
(text) => new Document({ pageContent: text })
);
await vectorStore.addDocuments(documents);
const retriever = vectorStore.asRetriever(5);
const retrieverTool = createRetrieverTool(retriever, {
name: "searchProperNouns",
description:
"Use to look up values to filter on. Input is an approximate spelling " +
"of the proper noun, output is valid proper nouns. Use the noun most " +
"similar to the search.",
});
Let’s try it out:
console.log(await retrieverTool.invoke({ query: "Alice Chains" }));
Alice In Chains
Alanis Morissette
Jagged Little Pill
Angel Dust
Amy Winehouse
This way, if the agent determines it needs to write a filter based on an artist along the lines of “Alice Chains”, it can first use the retriever tool to observe relevant values of a column.
Putting this together:
// Add to system message
let suffix =
"If you need to filter on a proper noun like a Name, you must ALWAYS first look up " +
"the filter value using the 'search_proper_nouns' tool! Do not try to " +
"guess at the proper name - use this function to find similar ones.";
const system = systemMessage + suffix;
const updatedTools = tools.concat(retrieverTool);
const agent2 = createReactAgent({
llm: llm,
tools: updatedTools,
prompt: system,
});
let inputs4 = {
messages: [
{ role: "user", content: "How many albums does alis in chain have?" },
],
};
for await (const step of await agent2.stream(inputs4, {
streamMode: "values",
})) {
const lastMessage = step.messages[step.messages.length - 1];
prettyPrint(lastMessage);
console.log("-----\n");
}
[human]: How many albums does alis in chain have?
-----
[ai]:
Tools:
- searchProperNouns({"query":"alis in chain"})
-----
[tool]: Alice In Chains
Alanis Morissette
Up An' Atom
A-Sides
Jagged Little Pill
-----
[ai]:
Tools:
- query-sql({"input":"SELECT COUNT(*) FROM albums WHERE artist_name = 'Alice In Chains'"})
-----
[tool]: QueryFailedError: SQLITE_ERROR: no such table: albums
-----
[ai]:
Tools:
- list-tables-sql({"input":""})
-----
[tool]: Album, Artist, Customer, Employee, Genre, Invoice, InvoiceLine, MediaType, Playlist, PlaylistTrack, Track
-----
[ai]:
Tools:
- info-sql({"input":"Album"})
- info-sql({"input":"Artist"})
-----
[tool]: CREATE TABLE Artist (
ArtistId INTEGER NOT NULL, Name NVARCHAR(120) )
SELECT * FROM "Artist" LIMIT 3;
ArtistId Name
1 AC/DC
2 Accept
3 Aerosmith
-----
[ai]:
Tools:
- query-sql({"input":"SELECT COUNT(*) FROM Album WHERE ArtistId = (SELECT ArtistId FROM Artist WHERE Name = 'Alice In Chains')"})
-----
[tool]: [{"COUNT(*)":1}]
-----
[ai]: Alice In Chains has released 1 album.
-----
As we can see, both in the streamed steps and in the LangSmith
trace,
the agent used the searchProperNouns tool in order to check how to
correctly query the database for this specific artist.